CLB 深度解析:LUT、MUX 与 Carry Chain 的协同之道
💡 上一篇文章我们了解了 FPGA 芯片的六级架构层次。现在让我们把”显微镜”对准最核心的那一层——CLB。
你写的每一行 Verilog 代码,无论是
assign y = a & b,还是c = a + b,最终都会变成 CLB 内部的 LUT 查表、MUX 选路、Carry Chain 传进位。理解 CLB 内部这三个组件如何分工协作,是写出高效 FPGA 代码的底层功夫。这篇文章会带你深入 Xilinx 7 系列 CLB 的内部结构,用 Verilog 代码 + Vivado 综合结果的方式,让你亲眼看到代码是如何变成硬件的。
目录
- 1. CLB 全景:两个 Slice 的世界
- 2. LUT:用查表代替计算的天才设计
- 3. MUX:LUT 的得力助手
- 4. Carry Chain:算术运算的高速公路
- 5. SliceL vs SliceM:标准版与增强版
- 6. 设计启示:如何写出对 CLB 友好的代码
- 7. 总结
- 常见问题
- 参考资料
1. CLB 全景:两个 Slice 的世界
在 Xilinx 7 系列 FPGA 中,一个 CLB 包含 2 个 Slice,两个 Slice 之间没有直接连线,各自独立工作。CLB 在芯片中按列排列,这是 ASMBL 架构的特点。
每个 Slice 内部包含:
| 组件 | 数量 | 核心作用 |
|---|---|---|
| LUT6 | 4 个 | 实现任意 6 输入组合逻辑 |
| MUX | 3 个 | 扩展 LUT 的逻辑宽度 |
| Carry Chain(CARRY4) | 1 条 | 加速算术运算的进位传播 |
| FF(触发器) | 8 个 | 存储数据,实现时序逻辑 |
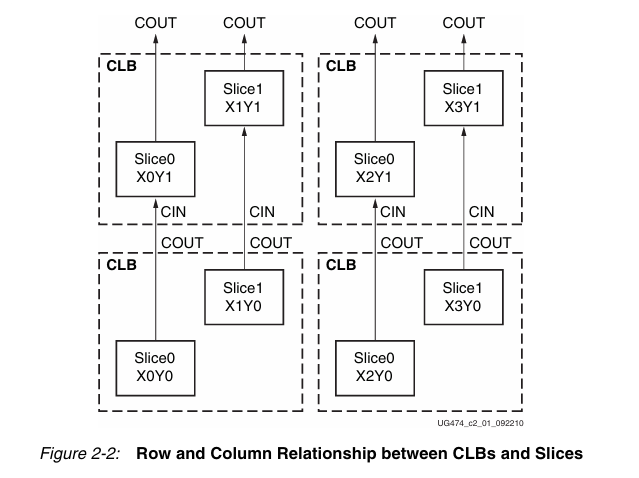 而一个 Slice 中的结构如下:
而一个 Slice 中的结构如下:
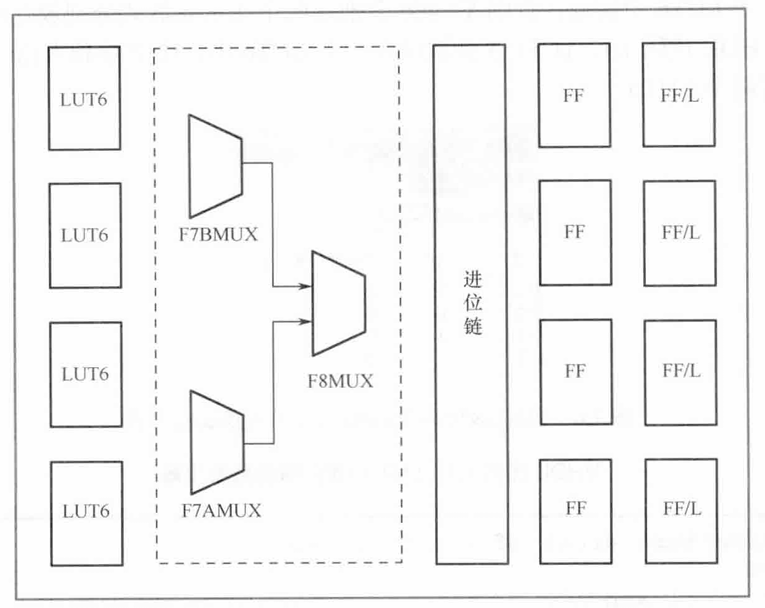
这四种组件各司其职,又紧密配合。接下来我们逐一深入。
2. LUT:用查表代替计算的天才设计
2.1 LUT 的本质:一个 64-bit 的小型 ROM
LUT(Look-Up Table,查找表) 是 FPGA 实现组合逻辑的核心。它的工作原理出奇地简单:
- 一个 6 输入 LUT 内部有 2⁶ = 64 个 SRAM 存储单元
- 6 个输入信号作为地址线,选中其中一个存储单元
- 被选中的存储单元中预存的值(0 或 1)就是 LUT 的输出
配置 FPGA 时,综合工具会把你的逻辑函数的真值表写入这 64 个 SRAM 单元。运行时,LUT 不做任何”计算”——它只是”查表”。
2.2 一个具体的例子
用 LUT 实现一个 6 输入与门 Y = A & B & C & D & E & F:
assign out = a & b & c & d & e & f;综合工具会把真值表写入 LUT:64 个存储单元中,只有地址 111111 对应的单元存 1,其余 63 个都存 0。
在 Vivado 中综合后,你会看到它被映射成一个 LUT6,INIT 值为 64'h8000000000000000——正好是第 63 位(最高位)为 1。
LUT 的精妙之处:不管你实现什么 6 输入逻辑函数——与门、或门、异或门、还是任意复杂的布尔表达式——消耗的资源和延迟都完全相同。因为它不是”计算”结果,而是”查表”。
2.3 LUT6 的内部结构:两个 LUT5 + 一个 MUX
一个 LUT6 实际上由两个独立的 LUT5 和一个 2:1 MUX 组成:
- 两个 LUT5 共享 A1~A5 五个输入
- A6 作为 MUX 的选择信号
- 当作 LUT6 使用时:A6 选择哪个 LUT5 的结果输出到 O6
- 当作两个 LUT5 使用时:A6 固定为 1,两个 LUT5 分别从 O5 和 O6 输出
这种**可分形(Fracturable)**设计非常聪明——如果你的设计中有两个 5 输入的逻辑函数恰好共享相同的输入,综合工具可以把它们塞进同一个 LUT6,提高资源利用率。
2.4 LUT 的代价:面积换灵活性
LUT 的灵活性是有代价的。实现一个 6 输入与门:
- 用逻辑门:5 个与门 × 6 个 MOS 管 = 30 个晶体管
- 用 LUT6:64 个 SRAM 单元 × 6 个晶体管 = 384+ 个晶体管(还不算译码电路)
FPGA 的通用性,本质上是用面积换来的。这也是为什么同等功能下,FPGA 的功耗和面积都大于 ASIC。
💬 你可能会问:如果我的逻辑超过 6 个输入怎么办?
综合工具会自动用多个 LUT 级联来实现。比如一个 8 输入的比较器需要 2~3 个 LUT 级联完成。级联越多,逻辑级数越深,延迟越大——这就是为什么 FPGA 设计要关注”逻辑级数”,必要时用流水线寄存器切割长组合逻辑路径。
3. MUX:LUT 的得力助手
3.1 Slice 中的三个专用 MUX
每个 Slice 包含 3 个专用 MUX:
| MUX | 输入来源 | 输出去向 | 实现的功能 |
|---|---|---|---|
| F7AMUX | LUT-A 和 LUT-B 的 O6 输出 | F8MUX 或直接输出 | 7 输入逻辑 / 8:1 MUX |
| F7BMUX | LUT-C 和 LUT-D 的 O6 输出 | F8MUX 或直接输出 | 7 输入逻辑 / 8:1 MUX |
| F8MUX | F7AMUX 和 F7BMUX 的输出 | 直接输出 | 8 输入逻辑 / 16:1 MUX |
这三个 MUX 的连接关系是固定的:F7MUX 只能接 LUT 的输出,F8MUX 只能接 F7MUX 的输出。
3.2 从 4:1 到 16:1:MUX 的级联扩展
通过 LUT + 专用 MUX 的组合,一个 Slice 可以实现不同规模的多路选择器:
| MUX 规模 | 所需资源 | 说明 |
|---|---|---|
| 4:1 MUX | 1 个 LUT6 | 4 数据 + 2 选择 = 6 输入,刚好一个 LUT |
| 8:1 MUX | 2 个 LUT6 + 1 个 F7MUX | 每个 Slice 可以放 2 个 |
| 16:1 MUX | 4 个 LUT6 + 2 个 F7MUX + 1 个 F8MUX | 每个 Slice 只能放 1 个 |
3.3 为什么不全用 LUT 实现 MUX?
你可能会想:既然 LUT6 可以实现 2:1 MUX,为什么还需要专用 MUX?
两个关键原因:
- 资源效率:用 LUT6 实现 2:1 MUX,有 3 个输入被浪费了。专用 MUX 不占用 LUT 资源
- 布线质量:一个 Slice 只有 4 个 LUT6。如果用纯 LUT 实现 16:1 MUX,需要 5 个 LUT,第 5 个必须布线到其他 Slice,路径长度不一致容易产生毛刺。而 LUT + 专用 MUX 的组合全部在一个 Slice 内完成,布线长度基本一致
💡 工程师手记:我曾经在一个高频设计中遇到 MUX 路径的时序违例。分析后发现是一个 32:1 MUX 被综合成了多级 LUT 级联,跨越了多个 Slice。后来改用树形结构 + 流水线寄存器,把 MUX 拆成两级 8:1,每级都在一个 Slice 内完成,时序立刻收敛了。
4. Carry Chain:算术运算的高速公路
4.1 为什么需要专用进位链?
当你写 c = a + b 时,每一位的计算结果不仅取决于当前输入,还取决于低位传来的进位。
如果用通用 LUT 和布线来传递进位信号,32 位加法器的进位要穿过 32 级 LUT + 32 段通用布线,延迟会非常大。
Carry Chain 就是专门给进位信号开辟的”高速公路”——它在 Slice 内部提供了一条低延迟的专用通路,让进位信号可以快速地从一位传到下一位。
4.2 CARRY4 的结构
7 系列 FPGA 的每个 Slice 包含一个 CARRY4 单元,可以处理 4 位的进位传播。它包含:
| 组件 | 数量 | 作用 |
|---|---|---|
| MUXCY | 4 个 | 选择是传递进位还是使用本级生成的进位 |
| XOR 门 | 4 个 | 计算每一位的”和”(Sum) |
信号流向:
- S0~S3(来自 LUT 的 O6 输出):进位链的”传播”信号
- DI1~DI4(来自 LUT 的 O5 输出或旁路输入):进位链的”生成”信号
- CIN:来自下方 Slice 的进位输入
- CO0~CO3:每一位的进位输出,其中 CO3 连接到上方 Slice 的 CIN
- O0~O3:每一位的求和结果
4.3 进位链的级联
一个 CARRY4 处理 4 位。对于更宽的运算:
- 8 位加法器:需要 2 个 CARRY4(同一 CLB 内的 2 个 Slice)
- 16 位加法器:需要 4 个 CARRY4(2 个 CLB)
- 32 位加法器:需要 8 个 CARRY4(4 个 CLB)
进位链在 Slice 之间垂直级联——这也是为什么 CLB 采用列状排列的原因之一。
⚠️ 设计注意:进位链的传播延迟随位宽线性增长。如果你的加法器位宽很大(比如 64 位)且时钟频率很高,可能需要用流水线把加法拆成多级。另外,进位链不能跨越 SLR 边界。
💡 工程师手记:我曾经在一个 200 MHz 的设计中用了一个 48 位的累加器,时序报告显示关键路径延迟超标 0.3 ns。分析后发现是 Carry Chain 太长——48 位需要 12 个 CARRY4 级联,跨越了 6 个 Slice。解决方案是把 48 位加法拆成两级流水线(低 24 位先加,高 24 位下一拍再加),时序立刻收敛。理解 Carry Chain 的物理结构,能帮你快速判断“这个加法器能跑多快”。
4.4 你不需要手动使用 Carry Chain
好消息是:当你写 c = a + b 或 c = a - b 时,综合工具会自动识别并使用 Carry Chain。你不需要手动例化 CARRY4 原语。
但理解 Carry Chain 的存在,能帮你:
- 看懂综合报告中的 Carry Chain 使用情况
- 理解为什么加法器的时序比同等复杂度的纯逻辑要好
- 在时序不满足时,知道可以通过流水线拆分来优化
5. SliceL vs SliceM:标准版与增强版
每个 CLB 包含 2 个 Slice,但这 2 个 Slice 不一定相同。Xilinx 将 Slice 分为两种类型:
核心区别
| 特性 | SliceL(Logic) | SliceM(Memory) |
|---|---|---|
| LUT 功能 | 只能做查找表 | 查找表 + 分布式 RAM + 移位寄存器 |
| LUT 可写性 | 只读(配置后固定) | 可读可写(运行时可更新) |
| 数量比例 | 约占 2/3 | 约占 1/3 |
| 典型用途 | 通用逻辑、状态机、控制逻辑 | 小型 FIFO、延迟线、分布式缓存 |
SliceM 的两个超能力
超能力 1:分布式 RAM
SliceM 中的 LUT 可以配置为小型 RAM:
- 单个 LUT → 64×1 bit 单端口 RAM
- 多个 LUT 组合 → 更大容量或多端口 RAM
适用场景:需要极低延迟的小容量存储(<64 bit),比如小型查找表、寄存器文件。
超能力 2:移位寄存器(SRL)
SliceM 中的 LUT 可以配置为高效的移位寄存器:
- 单个 LUT → 最多 32 位移位寄存器(SRL32)
- 4 个 LUT 级联 → 最多 128 位移位寄存器
适用场景:数据延迟线、流水线对齐、去抖动。一个 LUT 就能替代 32 个触发器,资源效率极高。
SliceM 的这两个超能力非常实用,但也有不少坑——比如 SRL 不能带复位信号,否则会退化为触发器链。下一篇文章我们会深入展开 SRL 的工作原理和正确使用姿势,以及触发器的设计陷阱。
💬 你可能会问:综合工具怎么知道该用 SliceL 还是 SliceM?
你不需要手动选择。综合工具会根据你的代码自动判断:普通逻辑映射到 SliceL,需要分布式 RAM 或 SRL 的逻辑映射到 SliceM。你只需要确保代码风格正确(比如 SRL 不能带复位信号),工具就能正确推断。
6. 设计启示:如何写出对 CLB 友好的代码
理解了 CLB 的内部结构,以下是几条实用的设计建议:
6.1 善用触发器做流水线
每个 Slice 有 8 个 FF,整个 FPGA 的触发器资源非常充裕。不要吝啬使用流水线寄存器——它们能有效切割长组合逻辑路径,提升时钟频率。
6.2 减少独特的控制信号
同一个 Slice 内的 8 个 FF 共享时钟(CLK)、时钟使能(CE)和置位/复位(S/R)信号。如果你的设计中有太多不同的控制信号组合,FF 会被分散到更多的 Slice 中,降低资源利用率。
6.3 让综合工具推断专用资源
- 写
c = a + b,工具会自动用 Carry Chain - 写移位寄存器时不要加复位信号,工具才能推断为 SRL
- 写小容量 RAM 时用同步读写风格,工具会自动选择分布式 RAM 或 Block RAM
6.4 关注逻辑级数
当综合报告显示某条路径的逻辑级数(Logic Levels)过高时,意味着信号要穿过太多级 LUT。解决方案:
- 插入流水线寄存器
- 重构逻辑,减少单级的输入数量
- 检查是否有不必要的优先级编码(
if-else链 vscase)
7. 总结
| 组件 | 核心作用 | 关键数字 | 你需要记住的一件事 |
|---|---|---|---|
| LUT6 | 实现任意 6 输入组合逻辑 | 每 Slice 4 个 | 查表不计算,任意函数延迟相同 |
| F7/F8 MUX | 扩展 LUT 的逻辑宽度 | 每 Slice 3 个 | 16:1 MUX 可在单个 Slice 内完成 |
| CARRY4 | 加速算术运算进位传播 | 每 Slice 1 条 | 写 a+b 自动使用,无需手动例化 |
| FF | 存储数据,实现时序逻辑 | 每 Slice 8 个 | 资源充裕,大胆用流水线 |
| SliceM 特殊能力 | 分布式 RAM + SRL | 约占 1/3 Slice | SRL 不能带复位,否则退化为 FF 链 |
CLB 是 FPGA 的”逻辑心脏”。LUT 负责”想”(组合逻辑),FF 负责”记”(时序逻辑),Carry Chain 负责”算”(算术运算),MUX 负责”选”(信号路由)。四者协同,构成了 FPGA 实现任意数字逻辑的基础能力。
常见问题
Q1:一个 LUT6 最多能实现多大的 MUX?
4:1 MUX。因为 4:1 MUX 需要 4 个数据输入 + 2 个选择输入 = 6 个输入,刚好用满 LUT6 的 6 个输入端口。5:1 MUX 需要 8 个输入,超出了单个 LUT6 的能力。
Q2:为什么 Vivado 把我的 2:1 MUX 映射到 LUT 而不是专用 MUX?
Slice 内的专用 MUX(F7MUX、F8MUX)的输入只能来自 LUT 的输出,它们是用来扩展 LUT 逻辑宽度的,不是用来替代 LUT 实现小型 MUX 的。2:1 MUX 是一个简单的 3 输入组合逻辑,完全在 LUT 的能力范围内,所以工具直接用 LUT 实现。
Q3:Carry Chain 能用于除法运算吗?
Carry Chain 主要优化的是加法、减法和比较运算。除法运算通常需要更复杂的逻辑结构(如迭代除法器或查找表),不能直接利用 Carry Chain。如果需要高性能除法,建议使用 DSP Slice 或 Vivado 的 IP 核。
Q4:SliceL 和 SliceM 的比例可以调整吗?
不能。SliceL 和 SliceM 的比例是芯片制造时就固定的(通常约 2:1)。如果你的设计需要大量分布式 RAM 或 SRL,需要在选型时关注目标芯片的 SliceM 数量。
参考资料
- Xilinx/AMD,UG474: 7 Series FPGAs Configurable Logic Block User Guide
- Xilinx/AMD,UG574: UltraScale Architecture CLB User Guide
- Xilinx/AMD,UG384: Spartan-6 FPGA Configurable Logic Block User Guide
系列导航:本文是「FPGA 内部资源深度解析」系列第 2 篇。
如果这篇文章对你有帮助,欢迎点赞、收藏,也欢迎在评论区分享你在 CLB 资源优化方面的经验。