FPGA的内部资源
现代FPGA内部就是一片可以编程的海洋,这些逻辑通常以阵列的形式排布,其内部结构可以分为以下几大类:
- 可编程逻辑单元
- 可编程IO单元
- 可编程互联资源
- 专用硬核IP(知识产权核如BlockRAM、PLL、DSP、SerDes等)
- 布线资源
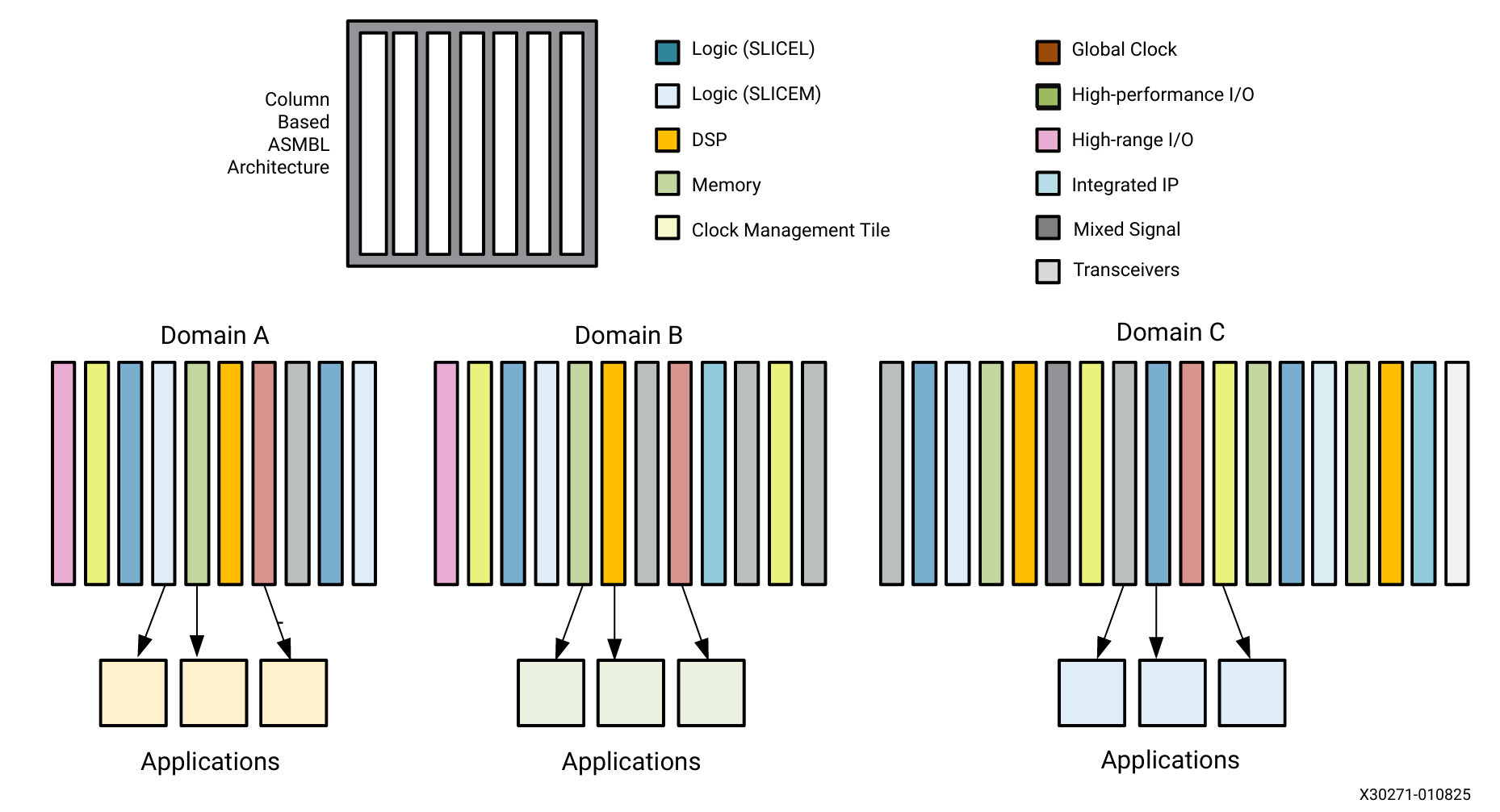
以Xlinx为例,最新系列FPGA采用的是ASMBL(Advanced Silicon Modular Block)架构。在 ASMBL架构中,每类资源以列形式存在,如下图所示:
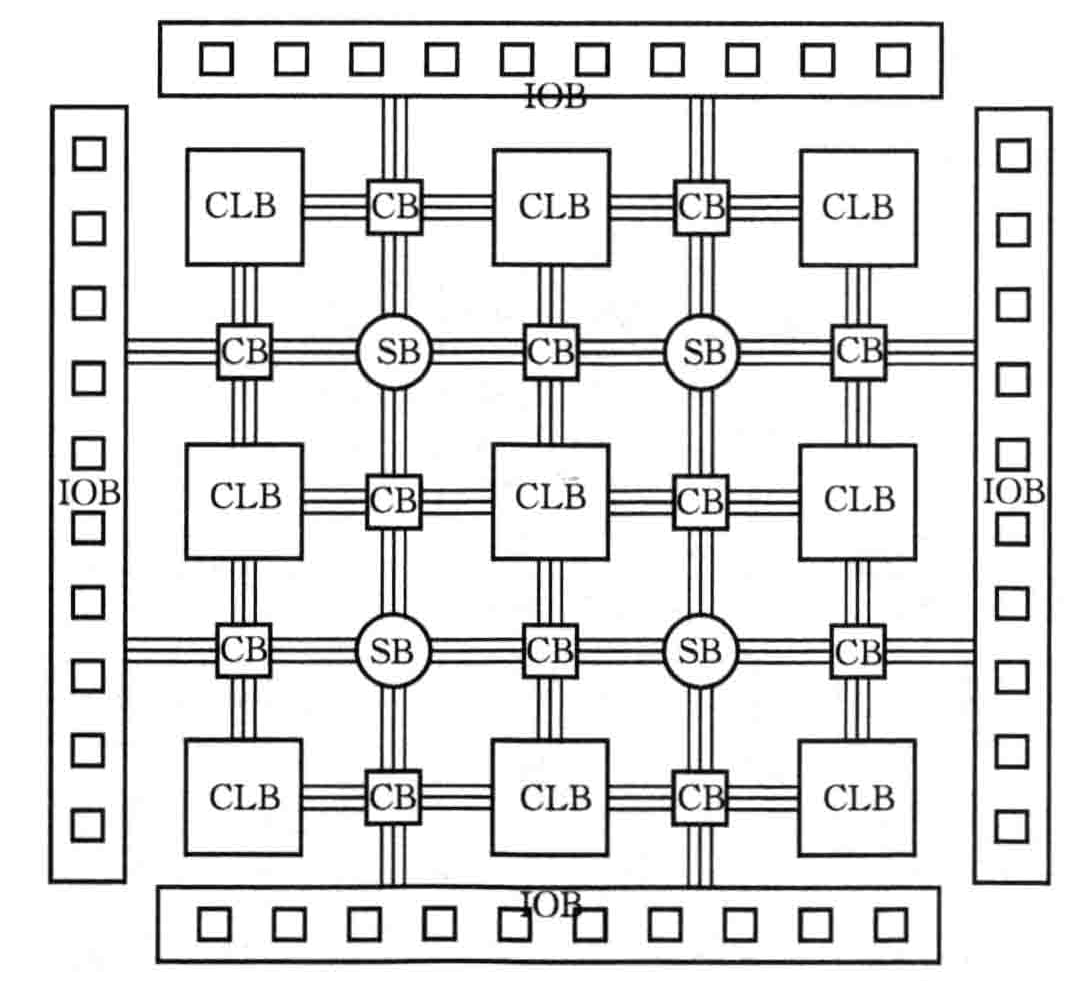
下图所示为xlinx7系列FPGA内部结构图,从中可以看出出FPGA芯片主要由三大部分组成:可编程逻辑单元、可编程IO单元和可编程互联资源。此外还有大量的CB和SB资源,用于连接可编程逻辑单元和可编程IO单元。
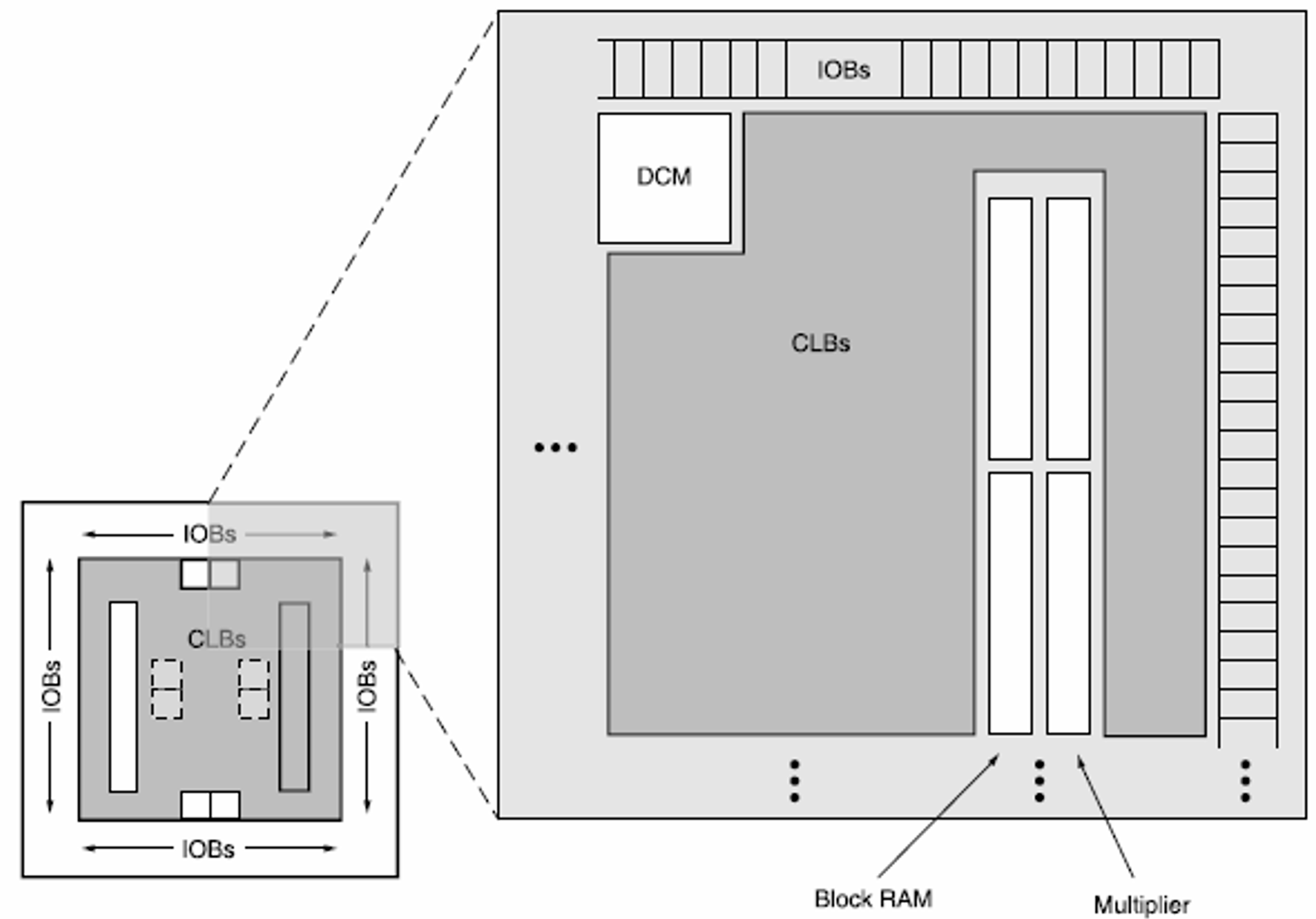
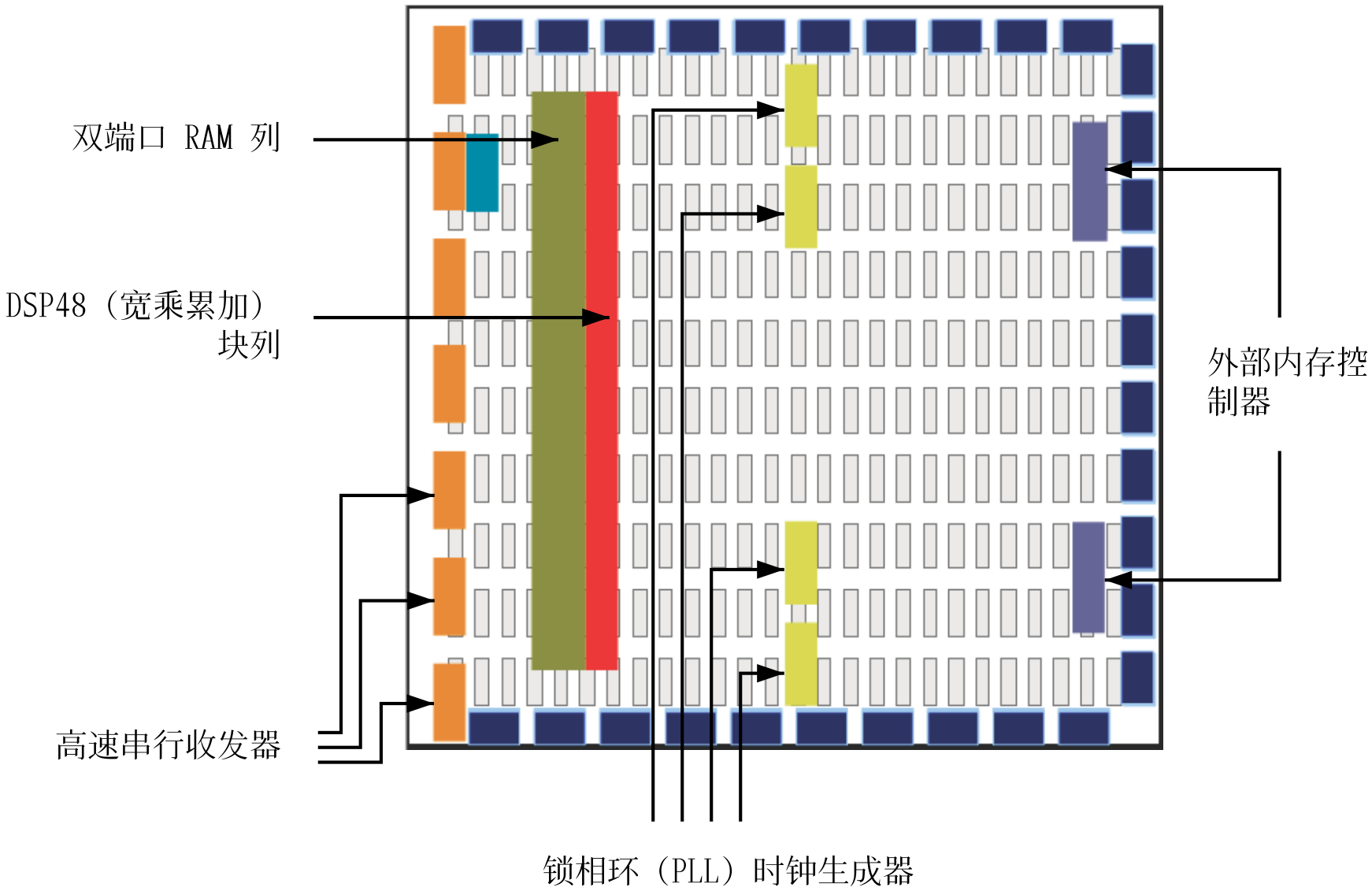
视角进一步拉远,可以看到专用硬核资源(如BlockRAM、PLL、DSP、SerDes等)以列的形式存在,用于实现特定的功能。如下图所示,从左到右分别为:BlockRAM、PLL、DSP、SerDes。
1. 可配置逻辑资源块(Configurable Logic Block)
可配置逻辑资源块是 FPGA 中实现数字逻辑功能的最核心、最基本单元。它在FPGA芯片中占的比重最大。通过编程对这些可配置逻辑资源块进行配置以及设置它们之间的连接关系,可以实现任意的组合逻辑与时序逻辑功能。可配置逻辑资源块就好比是数字电路世界中的“积木块”,它们形态各异,功能也有所区别,通过“搭积木”的方式可以利用 FPGA 实现想要的数字逻辑功能。
不同厂商叫法不同(Xilinx 称 CLB,即Configurable Logic Block; Intel/Altera 称 LAB,即Logic Array Module),但功能类似。Xilinx把一个CLB划分为若干个slice,每个slice中一般又包含若干个LUT、寄存器、进位链和复用器等;Altera把一个ALM划分为若干个ALUT和寄存器等,而每个ALUT中一般又可包含若干个LUT、全加器和复用器等。在FPGA芯片中,逻辑资源块是均匀分布的。
Xlinx的CLB中Slice结构如下图所示:
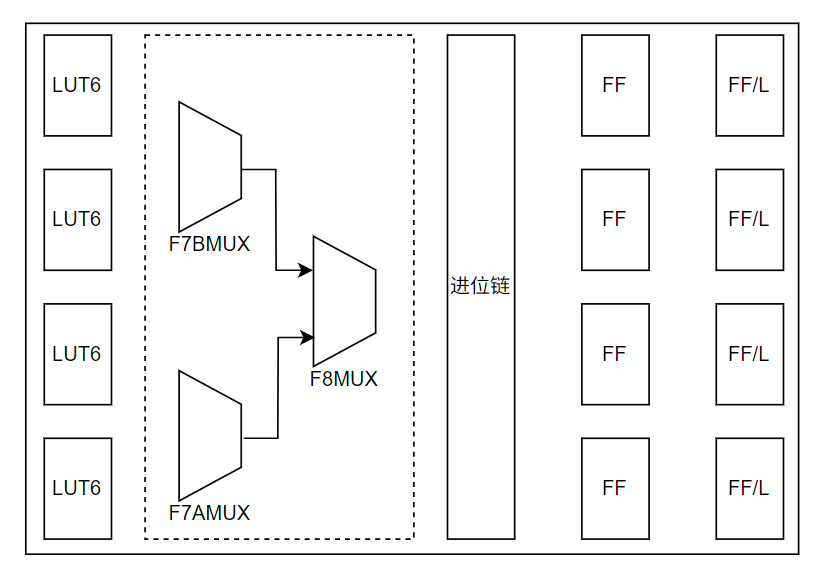
从7系列开始,Xlinx将Slice分为SliceL和SliceM两类,每个可配置逻辑块可包含两个 SliceL 型切片,或一个 SliceL 型与一个 SliceM 型切片的组合。一般情况下,CLB中比例SLICEL:SLICEM = 2:1。SliceL和SliceM的主要区别在于:
- SliceL (Logic Slice - 逻辑切片):
- 基本功能:SliceL 主要用于实现通用的组合逻辑和时序逻辑。
- 包含组件:它包含了一定数量的 6 输入 LUT、触发器、进位逻辑和相关的多路选择器。
- 核心作用:主要用于搭建常规的逻辑电路,如状态机、数据通路、控制逻辑等。可以把它看作是标准的、只具备基础逻辑功能的 Slice。
- 记忆:“L” 可以理解为 Logic。
- SliceM (Memory Slice - 存储器切片):
- 基本功能:SliceM 具备 SliceL 的所有功能,也就是说,它同样可以实现通用的组合逻辑和时序逻辑。
- 包含组件:它也包含与 SliceL 相同数量的 6 输入 LUT、触发器、进位逻辑和多路选择器。
- 附加功能(关键区别):SliceM 中的 LUT 具有一项特殊能力——它们除了可以配置为标准的 6 输入查找表来实现逻辑功能外,还可以被配置为以下两种模式:
- 分布式 RAM (Distributed RAM / DRAM):可以将 SliceM 中的 LUT 用作小型的、快速的片上存储器。这对于实现小容量的 FIFO、缓存、小型状态存储或者需要极低延迟访问的小型查找表非常有用。例如,一个 6 输入 LUT 可以配置成 64 x 1 的单端口 RAM 或 32 x 2 的双端口 RAM 等(具体配置取决于 LUT 和架构)。
- 移位寄存器 (Shift Register / SRL):SliceM 中的 LUT 还可以高效地实现移位寄存器功能,特别是可变长度的移位寄存器(如 32 位的 SRL 32 或 16 位的 SRL 16)。这对于数据流水线、延迟线、串并转换等应用非常方便且节省资源。
- 记忆:“M” 可以理解为 Memory (指分布式 RAM) 或 More (指比 SliceL 功能更多)。
1.1 LUT
LUT(Look-Up Table),中文叫”查找表”,是FPGA实现组合逻辑功能的最基本单元。其本质是一个小型的存储器(RAM),里面预先存储了某个逻辑函数的所有可能输出值。它的输入信号用作地址线,来选择存储器中预先存好的值,这个值就是 LUT 的输出。其工作原理如下图所示:
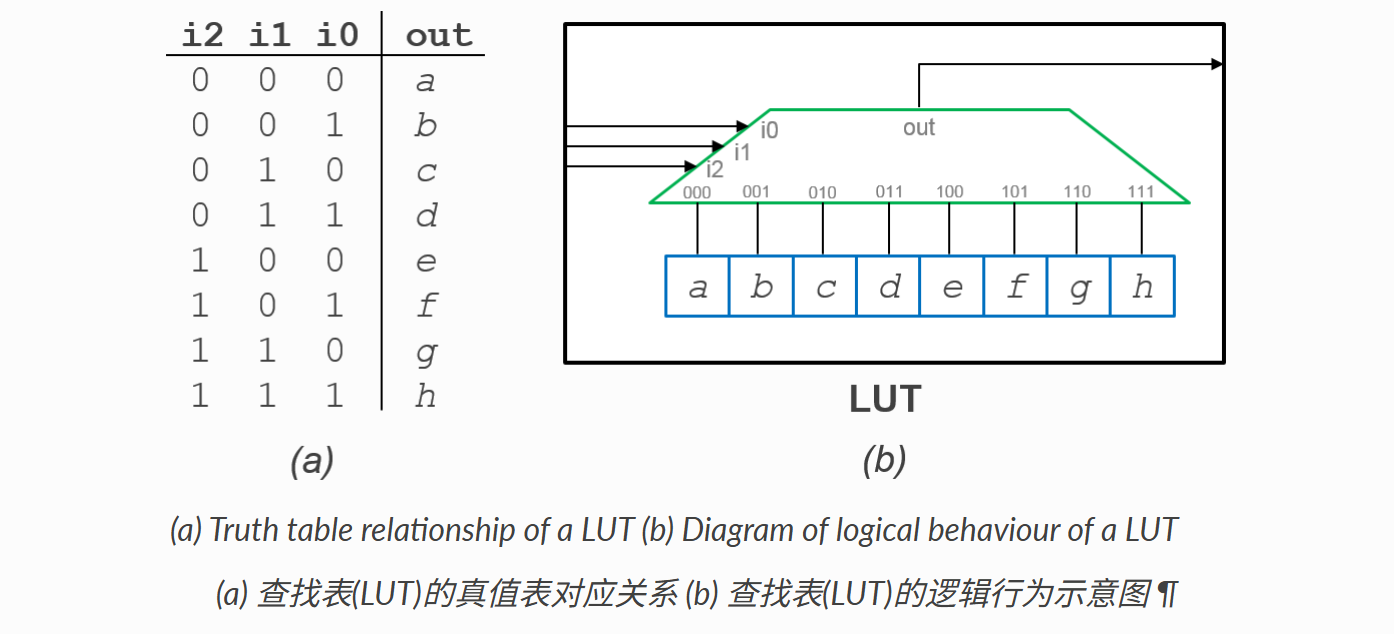
LUT 的输入数量(N)是衡量其能力的关键指标,现代 FPGA 多采用灵活的 6 输入 LUT。通过 LUT 可实现任意布尔逻辑运算,如下图所示,实际应用中常通过级联多个 LUT 来实现更复杂的逻辑运算。
Xlinx 7 系列 FPGA 芯片中,一个 CLB(可配置逻辑块)包含了 LUT 本质上就是一个 6 输入,64 深度(2 的六次方)的 ROM(SLiceM 中的 LUT 则是 RAM,因为可写)。通过将结果保存在其内部,使用时通过由输入构建的地址线对其进行查找,从而实现六输入的函数逻辑。
关于 LUT 的关键知识点如下:
-
基本概念与作用:
- 功能:LUT 的主要作用是实现用户的组合逻辑函数。任何一个具有 N 个输入的组合逻辑功能,都可以通过一个 N 输入的 LUT 来实现。
- 核心原理:LUT 的本质是一个小型的、基于 SRAM(静态随机存取存储器)的存储器块。它的输入信号用作地址线,来选择存储器中预先存好的值,这个值就是 LUT 的输出。
- 可编程性:在 FPGA 配置(烧录比特流)时,会将用户逻辑函数对应的真值表写入到 LUT 内部的 SRAM 单元中。这样,同一个物理 LUT 硬件就可以根据配置内容实现不同的逻辑功能。
-
工作机制:
- 结构:一个 N 输入的 LUT(常写作 N-LUT)通常有 N 个输入端口和一个输出端口。其内部有 2^N 个 SRAM 存储单元,每个单元存储 1 比特(0 或 1)。
- 查找过程:
- N 个输入信号的值构成一个 N 位的二进制地址。
- 这个地址会选中 2^N 个 SRAM 单元中的某一个。
- 被选中的 SRAM 单元中存储的值(0 或 1)就被输出到 LUT 的输出端口。
- 举例 (3 输入 LUT 实现 3 输入与门):
- 一个 3 输入 LUT 有 2^3=8 个 SRAM 存储单元。
- 输入为 A, B, C。地址范围是
000到111。 - 要实现与门 (Y = A & B & C),在配置时,向 LUT 写入如下真值表:
- 地址
000-> 存0 - 地址
001-> 存0 - …
- 地址
110-> 存0 - 地址
111-> 存1
- 地址
- 当 FPGA 运行时,如果输入 A=1, B=1, C=1,地址
111被选中,LUT 输出存储在111位置的值,即1。如果输入是 A=1, B=0, C=1,地址101被选中,输出存储的值0。
-
关键参数 - 输入数量 (N):
- LUT 最重要的参数是其输入的数量 N。N 决定了一个 LUT 能实现逻辑函数的最大复杂度。
- 早期的 FPGA 使用 4 输入 LUT(4-LUT)。
- 现代主流的 FPGA(如 Xilinx 7 系列及以后,Intel Stratix/Arria/Cyclone 系列)普遍使用6 输入 LUT(6-LUT)。有些架构的 LUT 还更复杂,可能带有双输出或可以拆分成更小的 LUT 使用。
- N 值的影响:
- 更大的 N: 单个 LUT 能实现更复杂的逻辑功能,可能减少实现某个完整逻辑所需的 LUT 数量和逻辑级数(depth),有助于提高性能(减少延迟)和集成度。
- 更小的 N: 实现简单功能时可能更节省面积,但实现复杂功能需要更多 LUT 和更深的逻辑级联。
- 现代的 6-LUT 通常设计得非常灵活,比如 Xilinx 的 6-LUT 可以配置为:
- 一个 6 输入、1 输出的任意函数。
- 两个 5 输入、1 输出的函数(如果这两个函数共享部分输入)。这种能力称为可分形 LUT (Fracturable LUT),可以提高逻辑资源的利用率。
- LUT 最重要的参数是其输入的数量 N。N 决定了一个 LUT 能实现逻辑函数的最大复杂度。
-
LUT 与其他组件的关系:
- LUT 的输入通常来自所在逻辑单元(如 Slice)的输入、其他 LUT 的输出或触发器的输出。
- LUT 的输出可以直接输出到逻辑单元外部的布线资源,也可以连接到同一逻辑单元内的触发器(Flip-Flop)输入端,非常方便地实现时序逻辑(即 LUT 实现组合逻辑,其结果由触发器在一个时钟周期后锁存)。
-
特殊用途:
- 正如在 SliceM 中提到的,某些 LUT(位于 SliceM 中)由于其基于 SRAM 的特性,可以被特殊配置为分布式 RAM (Distributed RAM) 或 移位寄存器 (Shift Register, SRL),而不是作为标准逻辑查找表使用。
-
LUT 在实际设计中的应用:
- 示例1:简单组合逻辑
- 代码:
assign y = a & b;- 综合工具会将这个逻辑映射到1个LUT,只用到LUT的2个输入,另外4个输入悬空,查找表内容:只有当输入为”11”时输出1,其他都是0
- 示例2:复杂组合逻辑
- 代码:
assign equal = (a[3:0] == b[3:0]);- 需要8个输入(两个4位数),超过了单个LUT6的能力
- 综合工具会用多个LUT级联实现
- 可能用2-3个LUT完成
- 示例3:状态机的下一状态逻辑
- 代码:
always @(*) begin case(state_c) IDLE : if(start) state_n = S1; else state_n = IDLE; S1 : if(done) state_n = IDLE; else state_n = S2; // ... endcase end- 下一状态逻辑是组合逻辑,由LUT实现
- 根据当前状态和条件信号,通过LUT查表得到下一状态
- 示例1:简单组合逻辑
1.2 MUX
MUX(Multiplexer),中文叫“多路选择器”,是一种组合逻辑电路,它有多个数据输入端、一个数据输出端和一个或多个选择输入端。它的作用是根据选择输入端(Select Lines)的值,从多个数据输入端中选择一个,并将其信号传送到唯一的输出端。其模型和真值表如下图所示:
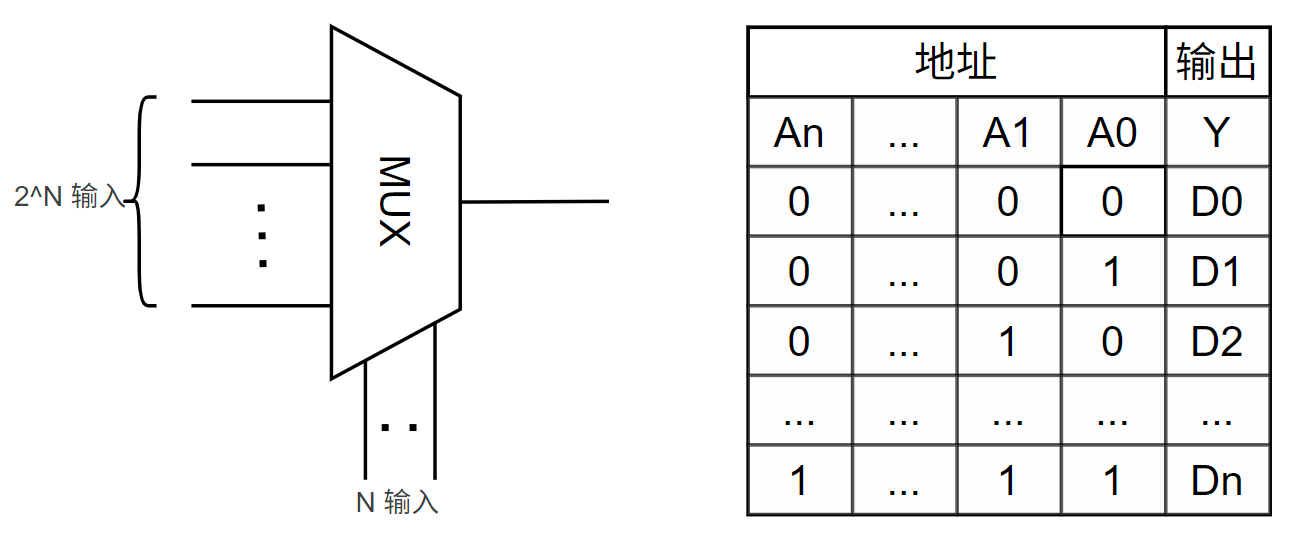
在FPGA的逻辑资源块中,有很多 MUX,根据用法可以分为两类:一类是配置 MUX,它的选通是在配置FPGA的时候确定的,因此它决定了所处逻辑资源块的功能;另一类是逻辑MUX,它的选通是由此时的内部逻辑决定的,因此它是内部逻辑的一部分。由此可见,MUX 是实现FPGA可配置性和信号路由的核心基础,理解 MUX 在 FPGA 中的作用对于理解布线延迟、资源利用率以及进行时序优化都非常有帮助。
关于MUX的关键知识点如下:
-
基本概念:
- 功能:MUX 的主要作用是根据选择输入端(Select Lines)的值,从多个数据输入端中选择一个,并将其信号传送到唯一的输出端。
- 核心原理:MUX 的本质是一个多路选择器,它有多个数据输入端、一个数据输出端和一个或多个选择输入端。它的作用是根据选择输入端(Select Lines)的值,从多个数据输入端中选择一个,并将其信号传送到唯一的输出端。
-
MUX的作用:
- 信号路由(Routing):FPGA 的互连网络使用 MUX 来连接不同逻辑块之间的信号路径。例如,在可编程互连点(Programmable Interconnect Points, PIP)中,MUX 决定信号从哪个输入线传输到输出线。
- 逻辑实现:MUX 可以用来构建组合逻辑电路。例如,在查找表(Look-Up Table, LUT)中,MUX 常用于实现多输入函数的选择逻辑。
- 时钟和控制信号管理:在时钟域交叉或复位信号分发中,MUX 用于选择不同的时钟源或控制路径。
- 资源优化:MUX 帮助减少逻辑占用,提高 FPGA 的利用率。例如,在数据路径中,MUX 可以动态选择数据源,节省专用硬件。
-
MUX的类型:
- LUT-based MUX:通过 LUT(通常是 4-6 输入的 SRAM 表)实现的逻辑 MUX。这是最常见的类型,用户可以用 HDL(如 Verilog 或 VHDL)描述 MUX 逻辑,然后工具(如 Vivado 或 Quartus)将其映射到 LUT 上。例如,一个简单的 2:1 MUX 可以用一个 LUT 实现。
- Dedicated MUX(专用 MUX):一些 FPGA 架构(如 Xilinx UltraScale 或 Intel Arria 系列)有内置的硬件 MUX 资源,这些是独立的硬核(Hard IP),不占用 LUT。它们用于高性能应用,如:
- Carry Chain MUX:在算术逻辑中,用于进位链的选择。
- Fractureable MUX:允许将一个大 MUX 分解成多个小 MUX,提高灵活性。
- Wide MUX:如 16:1 或 32:1 的宽 MUX,用于数据总线选择。
- Routing MUX:位于 FPGA 的布线通道中,用于全局或局部信号路由。这些 MUX 通常是多级级联的,以最小化延迟。
- I/O MUX:在输入/输出引脚处,用于选择不同的 I/O 标准或复用引脚功能。
-
MUX在实际设计中的应用:
- case 语句:这是最典型的生成MUX的结构
- 代码:
always @(*) begin case (sel) 2'b00: out = in0; 2'b01: out = in1; 2'b10: out = in2; 2'b11: out = in3; default: out = 'd0; endcase end- 上述代码会生成一个4-to-1 MUX,占用一个LUT6资源
- if-else 语句:这也是生成MUX的结构
- 代码:
always @(*) begin if (sel == 2'b00) out = in0; else if (sel == 2'b01) out = in1; else if (sel == 2'b10) out = in2; else out = in3; end- 上这同样会生成一个4-to-1 MUX,但它可能会产生优先级(Priority MUX),在时序上可能比case语句稍差。
- 三元运算符:这也是生成MUX的结构
- 代码:
assign out = (sel == 1'b0) ? in0 : in1;- 这会生成一个2-to-1 MUX,也会占用一个LUT6资源
- case 语句:这是最典型的生成MUX的结构
-
LUT-based MUX和硬核MUX的区别:
绝大多数中小型选择逻辑由LUT灵活实现。为了性能和效率,FPGA内部提供了专用的硬核MUX,用于将LUT的输出高效地级联起来,构建更宽、更快的数据选择路径。
| 特性 | 基于LUT的MUX | 专用硬核MUX (如MUXFx) |
|---|---|---|
| 实现方式 | 通过配置可编程的查找表(RAM) | 固化的、专门的硬件电路 |
| 适用场景 | 中小型的MUX(如2-to-1, 4-to-1)以及各种组合逻辑 | 大型、高性能的MUX(如8-to-1, 16-to-1, 32-to-1) |
| 灵活性 | 非常高,可以实现任何逻辑功能 | 低,只能用于多路选择 |
| 性能 | 性能适中,级联会增加延迟 | 非常高,延迟极低 |
| 资源 | 消耗通用的LUT逻辑资源 | 消耗专用的MUXFx资源,节省LUT |
1.3 SRL
SRL(Shift Register LUT),中文叫”移位寄存器查找表”,是Xilinx FPGA中SliceM特有的一种资源配置模式。传统上,移位寄存器由一系列级联的FF实现。它的作用是内部数据可以在移位脉冲(时钟信号)的作用下依次左移或右移。移位寄存器不仅可以存储数据,还可以用来实现数据的串并转换、分频、构成序列码发生器、序列码检测器、进行数值运算以及数据处理等。
现代FPGA利用LUT内部的SRAM结构,将原本用于存储逻辑函数真值表的存储单元重新配置为移位寄存器,实现高效的、可变长度的数据延迟功能。相比传统的触发器链实现方式,能够显著节省逻辑资源。
关于SRL的关键知识点如下:
-
基本概念:
- 定义:SRL是将SliceM中的LUT配置为移位寄存器的一种特殊模式。在这种模式下,LUT内部的64个SRAM单元(对应6-LUT的2^6=64个存储位置)被串联成一条移位寄存器链。
- 核心思想:利用LUT的存储特性,将数据逐时钟周期地在SRAM单元间移动,实现固定或可变长度的延迟。
- 资源优势:一个6-LUT配置为SRL后,可以实现最多32位的移位寄存器(SRL32),而传统方法需要32个独立的触发器(FF)。
-
工作原理:
- 数据输入(D):每个时钟周期,新数据从输入端进入
- 移位操作:所有已存储的数据向后移动一位
- 地址选择(A[4:0]):通过地址线选择输出哪一级的数据
- 地址0:输出最新输入的数据(延迟1个时钟)
- 地址1:输出延迟2个时钟的数据
- …
- 地址31:输出延迟32个时钟的数据
SRL的工作可以类比为一条”数据流水线”:
时钟周期: T0 T1 T2 T3 T4 ... T31
数据流向: [D] → [0] → [1] → [2] → [3] → ... → [31] → Q- 结构与端口:
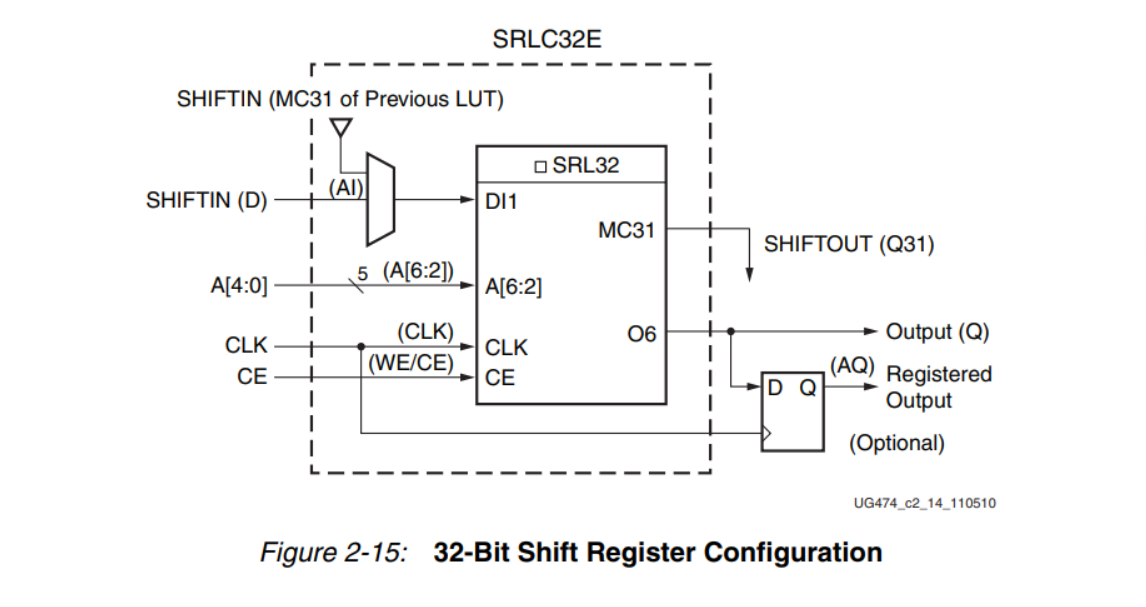
如图,典型的SRL32(32位移位寄存器)具有以下端口:
| 端口名 | 方向 | 位宽 | 说明 |
|---|---|---|---|
| CLK | 输入 | 1 | 时钟信号,每个上升沿触发移位 |
| CE | 输入 | 1 | 时钟使能,高电平时移位有效 |
| D | 输入 | 1 | 串行数据输入 |
| A[4:0] | 输入 | 5 | 地址选择信号,选择输出位置 |
| Q | 输出 | 1 | 数据输出 |
| Q31 | 输出 | 1 | 第31级的固定输出(可选) |
-
SRL在实际设计中的应用:
- 数据流水线延迟:
- 使用SRL可以实现固定或可变长度的数据延迟,适用于数据流水线中的时序对齐
- 代码:
// 应用场景:图像处理、视频处理中的行延迟、列延迟 // 功能:将8位数据延迟20个时钟周期 module pipeline_delay ( input wire clk, input wire ce, // 数据有效使能 input wire [7:0] data_in, // 输入数据 output reg [7:0] data_out // 输出数据(延迟20拍) ); // 参数定义 localparam DELAY_CYCLES = 20; // 为每个bit创建独立的移位寄存器 genvar i; generate for (i = 0; i < 8; i = i + 1) begin : srl_delay reg [DELAY_CYCLES-1:0] shift_reg; // 移位操作(自动推断为SRL) always @(posedge clk) begin if (ce) begin shift_reg <= {shift_reg[DELAY_CYCLES-2:0], data_in[i]}; end end // 输出同步寄存器 always @(posedge clk) begin data_out[i] <= shift_reg[DELAY_CYCLES-1]; end end endgenerate endmodule- 上述代码会消耗8个SRL32E资源,每个SRL32E可以实现32位移位寄存器。
- 多通道对齐:
- 使用SRL可以实现多通道对齐
- 代码:
// 4通道数据,各通道不同延迟 module multi_channel_align ( input wire clk, input wire [3:0] data_in, // 4个数据通道 output reg [3:0] data_out // 对齐后的输出 ); // 通道0: 直通(无延迟) always @(posedge clk) begin data_out[0] <= data_in[0]; end // 通道1: 延迟8拍 reg [7:0] delay_ch1; always @(posedge clk) begin delay_ch1 <= {delay_ch1[6:0], data_in[1]}; data_out[1] <= delay_ch1[7]; end // 通道2: 延迟16拍 reg [15:0] delay_ch2; always @(posedge clk) begin delay_ch2 <= {delay_ch2[14:0], data_in[2]}; data_out[2] <= delay_ch2[15]; end // 通道3: 延迟24拍 reg [23:0] delay_ch3; always @(posedge clk) begin delay_ch3 <= {delay_ch3[22:0], data_in[3]}; data_out[3] <= delay_ch3[23]; end endmodule - 去抖动电路:
- 使用SRL可以实现去抖动电路,适用于去抖动信号
- 代码:
// 应用场景:按键输入、开关信号处理 // 功能:采样16次,全0或全1才确认状态变化 module debounce_filter ( input wire clk, // 建议1kHz-10kHz采样时钟 input wire rst, input wire button_raw, // 原始按键输入(有抖动) output reg button_stable // 稳定的按键输出 ); // 16位移位寄存器(自动推断为SRL16E) reg [15:0] sample_shift; always @(posedge clk) begin if (rst) begin sample_shift <= 16'h0000; button_stable <= 1'b0; end else begin // 采样移位 sample_shift <= {sample_shift[14:0], button_raw}; // 全1时认为按键按下 if (&sample_shift) begin button_stable <= 1'b1; end // 全0时认为按键释放 else if (~|sample_shift) begin button_stable <= 1'b0; end // 其他情况保持当前状态 end end endmodule - 脉冲延迟与脉冲展宽:
- 使用SRL可以实现脉冲延迟与脉冲展宽,适用于脉冲信号的延迟与展宽
- 代码:
// 应用场景:LED指示、脉冲信号可视化 // 功能:先延迟,再展宽 module pulse_delay_stretch #( parameter DELAY = 5, parameter WIDTH = 20 )( input wire clk, input wire rst, input wire pulse_in, output reg pulse_out ); // 第一级:延迟 reg [DELAY-1:0] delay_shift; wire delayed_pulse; always @(posedge clk) begin if (rst) delay_shift <= {DELAY{1'b0}}; else delay_shift <= {delay_shift[DELAY-2:0], pulse_in}; end assign delayed_pulse = delay_shift[DELAY-1]; // 第二级:展宽 reg [WIDTH-1:0] stretch_shift; always @(posedge clk) begin if (rst) begin stretch_shift <= {WIDTH{1'b0}}; pulse_out <= 1'b0; end else begin stretch_shift <= {stretch_shift[WIDTH-2:0], delayed_pulse}; pulse_out <= |stretch_shift; end end endmodule
- 数据流水线延迟:
-
使用SRL的局限性与注意事项:
- 只存在于SliceM中:
- SRL只能在SliceM类型的Slice中实现
- SliceL不支持SRL模式
- 如果设计中大量使用SRL,需要确保有足够的SliceM资源
- 不支持异步复位:
- SRL没有专用的复位端口
- 如果需要复位功能,需要额外的逻辑控制或在初始化时预置数据
- 初始状态不确定:
- FPGA配置后,SRL内部的初始值是不确定的
- 如果应用对初始状态敏感,需要在开始使用前先”冲刷”(flush)移位寄存器
- 输出需要额外的触发器:
- SRL的输出Q是组合逻辑路径(经过内部MUX选择)
- 在很多设计中,为了保持时序清晰,需要在Q输出后添加一个触发器进行同步
- 这会额外消耗1个FF资源,并增加1个时钟周期的延迟
- 可变地址的时序挑战:
- 如果地址信号A是动态变化的,需要确保地址信号的时序满足要求
- 地址变化可能引入额外的时序路径
- 综合工具的识别:
- 需要使用特定的编码风格,综合工具才能自动推断出SRL
- 不当的写法可能导致综合为普通的触发器链
- 只存在于SliceM中:
1.4 Carry Chain
Carry Chain,中文叫”进位链”,是FPGA内部一种特殊且专用的硬件逻辑资源,它的核心目的是为了高效、快速地处理算术运算(尤其是加法和减法)中的进位信号传播。
关于Carry Chain的关键知识点如下:
-
为什么需要进位链?
- 在数字电路中,执行像加法这样的算术运算时,每一位的计算结果不仅取决于当前的输入位,还取决于来自前一位的进位(Carry-in)。
- 如果使用FPGA中的通用逻辑资源(如查找表LUT)来构建一个多位的加法器,那么每一位的进位信号需要通过LUT和FPGA的通用布线资源传递到下一位。
- 对于位数较多的加法器(例如32位或64位),这种通过通用逻辑和布线的进位传递方式会一层层累积延迟,导致加法器的整体运算速度非常慢,严重限制了FPGA可以达到的工作频率。
-
进位链到底是什么?
- 为了解决上述问题,FPGA厂商在芯片内部设计了专门用于快速传递进位信号的硬件通路,这就是进位链。
- 它通常是内嵌在FPGA的基本逻辑单元(如Xilinx的Slice或Intel/Altera的ALM/LAB)之中,并将这些逻辑单元在垂直方向上紧密连接起来。
- 可以把它想象成一条”高速公路”,专门给进位信号使用,让它能够快速地从一个逻辑单元传递到相邻的下一个逻辑单元。
-
进位链如何工作?(How it works)
- 当FPGA的逻辑单元被配置成执行算术运算(如全加器)时,其内部的特定硬件(通常与LUT协同工作)会计算出本位的和(Sum)以及向更高位的进位输出(Carry-out)。
- 这个进位输出信号不是进入通用的布线网络,而是直接送入专用的进位链通路。
- 这条通路将该信号极快地传递给物理上相邻(通常是上方)的逻辑单元,作为其进位输入(Carry-in)。
- 这样,进位信号就可以快速地“串行”穿过多个逻辑单元,大大减少了传播延迟。
-
进位链的优点 (Advantages)
- 显著提高性能:这是最主要的优点。极大地缩短了多位算术运算(加、减、比较、计数器等)的关键路径延迟,使得FPGA能够以更高的时钟频率运行这些运算。
- 节省通用资源:由于进位信号走了专用通道,就不需要占用宝贵的通用布线资源,这些资源可以留给其他逻辑连接使用。
- 更可预测的时序:专用硬件路径的延迟通常比通用布线路径的延迟更短且更稳定,有助于设计者进行时序分析和确保时序收敛。
-
如何使用进位链?(Usage)
- 在大多数情况下,设计者不需要直接手动控制进位链。
- 当你使用硬件描述语言(HDL,如Verilog或VHDL)编写算术运算代码时(例如
c = a + b;),综合工具(Synthesis Tool)会自动识别这是一个算术运算,并智能地利用FPGA底层的进位链资源来优化实现,以达到最佳的性能。 - 当然,对于需要极致优化或特殊控制的高级用户,FPGA厂商通常也提供了直接例化(Instantiate)底层进位链原语(Primitive)的方法,但这在常规设计中较少使用。
-
厂商实现差异 (Vendor Differences)
- 不同的FPGA厂商(如Xilinx、Intel/Altera、Lattice等)对其进位链的具体实现、命名和结构可能有所不同。
- 例如,Xilinx的现代FPGA中,一个Slice里的进位逻辑通常被称为
CARRY4(处理4位)或CARRY8(在某些系列中)。 - Intel (Altera) 的FPGA在其自适应逻辑模块(ALM)中集成了高效的加法器和进位链结构,有时会提到
carry-sum链等概念。 - 尽管具体实现有差异,但其核心目的和优势都是一致的:加速算术运算的进位传播。
1.5 DFF
DFF(D Flip-Flop),中文叫”D触发器”,是FPGA中实现时序逻辑的核心组件,用于存储信号状态并确保电路在时钟驱动下的同步操作。
Xlinx 的 7 系列 FPGA 芯片中 1个 CLB 有 2个 Slice,每个 SLice 中包含 8个FF。这 8 个 FF 可以分为两大类,其中 4 个只能配置为边沿敏感的 D 触发器(DFF),另外 4 个既可以配置为边沿敏感的 D 触发器又可以配置为电平敏感的锁存器(FF/L)。当后者被配置为锁存器时,前者不能使用。当这 8 个触发器用作 DFF 时,它们的控制端口包括时钟使能端 CE,置位/复位端 S/R 和时钟端 CLK 是共享的。 S/R 端口可以配置为同/异步复位或者同步/异步置位,且高有效。因此可以形成下面 4 种触发器:FDCE、FDPE、FDRE 和 FDSE:
| 原语(Primitive) | 功能描述 |
|---|---|
| FDCE | 异步复位 |
| FDPE | 异步置位 |
| FDRE | 同步复位 |
| FDSE | 同步置位 |
下图展示了单个 Slice中纯 DFF 模式以及 DFF/Latch 混合配置的结构:
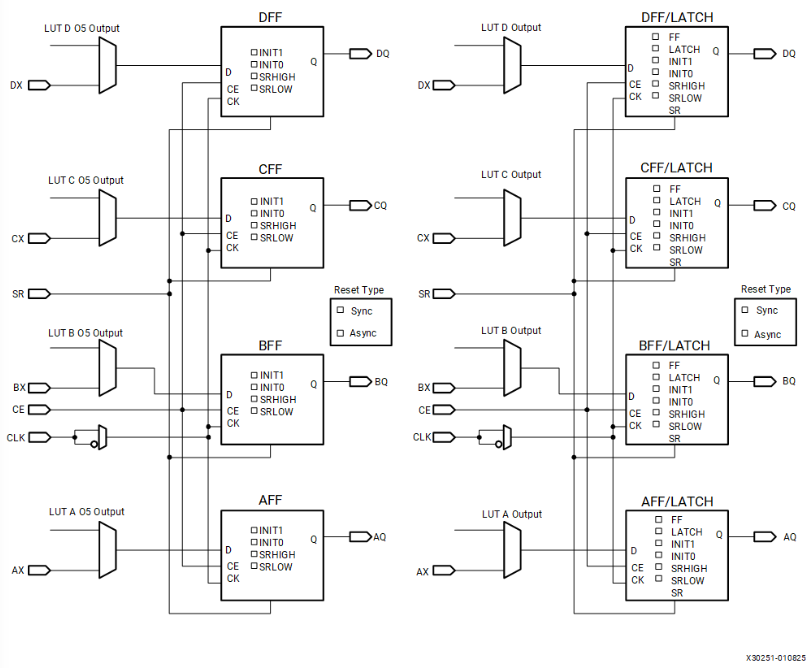
可以看到,DFF 的输入信号可通过两种方式驱动:一种是 D 输入可以通过 AFFMUX、BFFMUX、CFFMUX 或 DFFMUX 直接由 LUT 输出驱动;二是通过 AX、BX、CX 或 DX 绕过 LUT 以 BYPASS 方式直接输入。当配置为锁存器时,在 CLK(时钟信号)为低电平时,锁存器处于透明状态。
从图中还可以看到,一个 Slice 中 8 个 FF 的钟使能端 CE,置位/复位端 S/R 和时钟端 CLK 是共享的。尤其是半个Slice(通常包含4个触发器)中,触发器会共享一个可配置的 S/R 控制信号,这个 S/R 信号可以被配置为同步或异步,以及置位(Set)或复位(Reset/Clear)。若某个触发器启用了 SR 或 CE 功能,则该片内其他触发器也会通过相同的控制信号启用相应功能。因此 FF 无法实现复位和置位共存的情形。 因此,具有不同步/异步特性或不同置位/复位极性需求的触发器,会被工具划分到不同的“控制集”(Control Sets)中。这些控制集如果不能映射到单个Slice内共享的SR资源上,就会被分散到不同的Slice或Slice的不同部分。 正如上面提到,它们很可能被综合器和布局器识别为属于不同的控制集。为了满足这些特定的控制信号需求,工具可能会将它们放置到不同的Slice(或Slice的不同控制区域)中,以确保每个触发器都能正确接收和响应其独立的控制逻辑。时序、布线和整体设计优化也是重要的考量因素。
2. 可编程IO单元(IO Block)
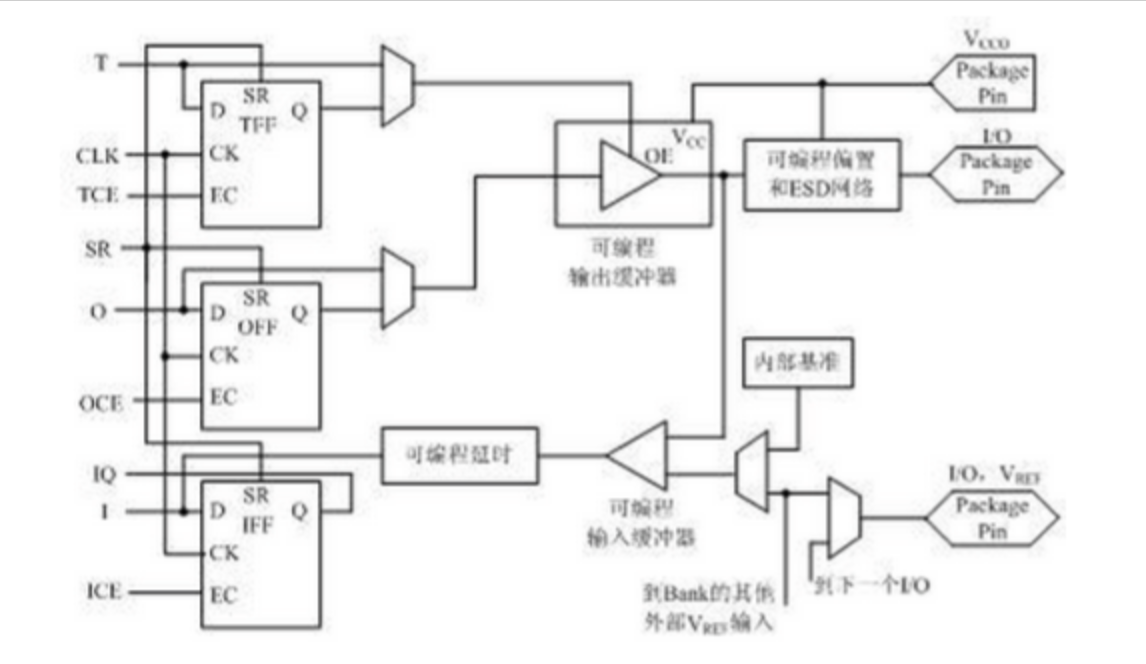
可编程IO单元(Input/Output Block)是FPGA芯片与外部世界进行数据交互的接口单元,位于FPGA芯片的周边区域。负责完成不同电气特性下对输入/输出信号的驱动与匹配要求。其结构如下图所示:
补充一张字体更清楚的
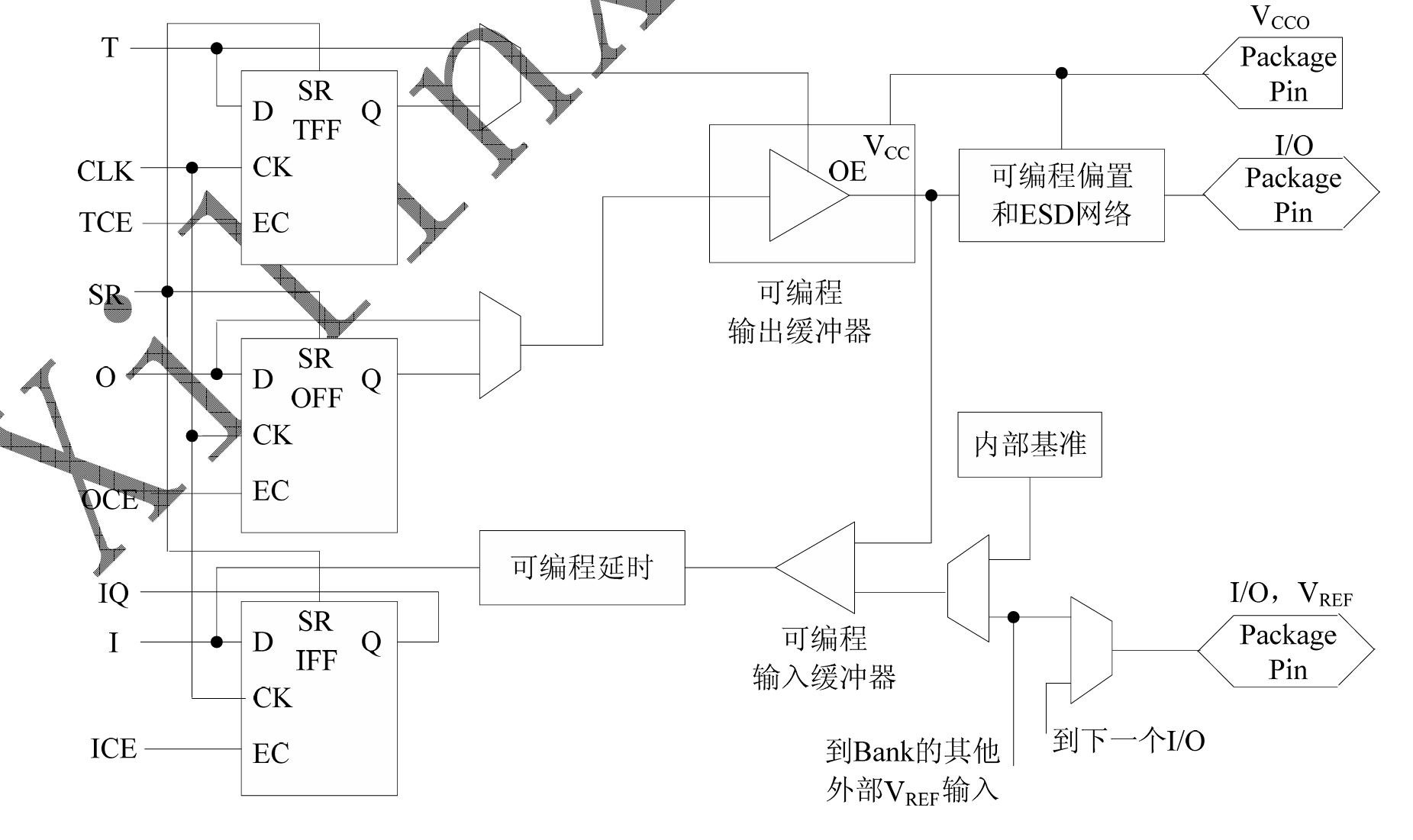
为了便于管理和适应多种电气标准,FPGA的IOB被划分为若干个bank,每个bank的接口标准由其接口电压VCCO决定, 一个bank只能有一种VCCO,但不同的bank的VCCO可以不同。只有相同电气标准的端口才能连接在一起,VCCO电压相同是接口标准的基本条件。
通过软件的灵活配置,每组IOB可以适配不同的电气标准与I/O物理特性,可以调整驱动电流的大小,可以改变上、下拉电阻。目前,I/O 口的频率也越来越高,一些高端的FPGA通过DDR寄存器技术可以支持高达2Gbps的数据速率。
2.1 IOB的内部结构
以Xilinx 7系列为例,IOB的典型结构包含以下组件:
| 组件 | 功能 | 说明 |
|---|---|---|
| PAD | 物理引脚 | 芯片封装上的实际金属引脚 |
| 输入缓冲器 | 电平转换与保护 | 将外部信号转换为内部逻辑电平 |
| 输出缓冲器 | 驱动能力 | 将内部信号驱动到外部负载 |
| 输入寄存器(IDDR) | 数据同步 | 可选的触发器,用于同步输入数据 |
| 输出寄存器(ODDR) | 数据同步 | 可选的触发器,用于同步输出数据 |
| 三态控制 | 方向控制 | 控制引脚为输出、输入或高阻态 |
| 上/下拉电阻 | 默认状态 | 可配置的内部上拉或下拉电阻 |
2.2 IOB支持的I/O标准
Xilinx 7系列FPGA的IOB支持多种I/O标准,这些标准决定了信号的电压电平、驱动强度和终端匹配方式:
单端标准(Single-ended):
- LVCMOS(Low Voltage CMOS):3.3V、2.5V、1.8V、1.5V、1.2V
- LVTTL(Low Voltage TTL):3.3V TTL兼容
差分标准(Differential):
- LVDS(Low Voltage Differential Signaling):高速低功耗
- TMDS(Transition Minimized Differential Signaling):用于HDMI/DVI
- RSDS、Mini-LVDS等
存储器接口标准:
- SSTL(Stub Series Terminated Logic):用于DDR、DDR2
- HSTL(High Speed Transceiver Logic)
- POD(Pseudo Open Drain):用于DDR3
2.3 IOB的关键特性
2.3.1 DDR寄存器(Double Data Rate)
IOB支持DDR技术,可以在时钟的上升沿和下降沿都进行数据采样或发送,从而将有效数据传输率翻倍。
IDDR(Input DDR):
// IDDR原语示例:在时钟的上升沿和下降沿同时采样
IDDR #(
.DDR_CLK_EDGE("OPPOSITE_EDGE"), // "OPPOSITE_EDGE"或"SAME_EDGE"
.INIT_Q1(1'b0), // Q1初始值
.INIT_Q2(1'b0), // Q2初始值
.SRTYPE("SYNC") // 复位类型:"SYNC"或"ASYNC"
) IDDR_inst (
.Q1(data_rise), // 输出:上升沿采样的数据
.Q2(data_fall), // 输出:下降沿采样的数据
.C(clk), // 输入:时钟
.CE(1'b1), // 输入:时钟使能
.D(data_in_pad), // 输入:来自PAD的数据
.R(1'b0), // 输入:复位
.S(1'b0) // 输入:置位
);ODDR(Output DDR):
// ODDR原语示例:在时钟的上升沿和下降沿同时输出
ODDR #(
.DDR_CLK_EDGE("OPPOSITE_EDGE"),
.INIT(1'b0),
.SRTYPE("SYNC")
) ODDR_inst (
.Q(data_out_pad), // 输出:到PAD的DDR数据
.C(clk), // 输入:时钟
.CE(1'b1), // 输入:时钟使能
.D1(data_rise), // 输入:上升沿输出的数据
.D2(data_fall), // 输入:下降沿输出的数据
.R(1'b0), // 输入:复位
.S(1'b0) // 输入:置位
);2.3.2 三态控制(Tri-state Control)
当IOB配置为双向端口时,需要三态控制来决定引脚的方向:
// 三态双向端口示例
module tristate_io (
input wire clk,
input wire oe, // 输出使能(1=输出,0=输入)
input wire [7:0] data_out, // 要输出的数据
output reg [7:0] data_in, // 读取的输入数据
inout wire [7:0] io_pad // 双向端口
);
// 输出控制
assign io_pad = oe ? data_out : 8'bz;
// 输入采样
always @(posedge clk) begin
data_in <= io_pad;
end
endmodule2.3.3 上/下拉电阻
IOB内部提供可配置的上拉或下拉电阻(通常在几十kΩ),用于:
- 防止悬空输入引脚
- 定义未驱动时的默认电平
在Vivado中配置:
# 约束文件(.xdc)中配置
set_property PULLUP TRUE [get_ports {button_in}]
set_property PULLDOWN TRUE [get_ports {unused_pin}]2.3.4 驱动强度(Drive Strength)
可以调整输出缓冲器的驱动电流,以匹配不同的负载和走线长度:
# 设置驱动强度(单位:mA)
set_property DRIVE 12 [get_ports {data_out[*]}]
# 可选值:2、4、6、8、12、16、24等(取决于I/O标准)更高的驱动强度:
- 优点:能驱动更重的负载、更长的走线
- 缺点:增加功耗、可能增加EMI(电磁干扰)
2.3.5 转换速率控制(Slew Rate)
控制输出信号的边沿速率:
set_property SLEW FAST [get_ports {clk_out}]
# 可选值:SLOW、FAST- FAST:更陡峭的边沿,适合高速信号,但EMI更大
- SLOW:较缓的边沿,降低EMI,适合低速信号
2.4 IOB的Bank组织结构
FPGA的IOB按Bank(组)进行管理。每个Bank共享同一个VCCO(I/O电压)。
关键规则:
-
同一Bank内的所有I/O必须使用兼容的电压标准
- 例如:Bank 14的VCCO=3.3V,则该Bank只能使用3.3V的I/O标准(LVCMOS33、LVTTL等)
-
HR Bank vs. HP Bank(高端FPGA):
- HR(High Range)Bank:支持1.2V~3.3V的I/O标准
- HP(High Performance)Bank:支持1.2V~1.8V,通常用于高速接口
-
跨Bank的差分对:
- 差分信号的P/N对必须在同一Bank内
2.5 IOB在实际设计中的应用场景
2.5.1 按键输入(带消抖)
module button_input (
input wire clk,
input wire rst,
input wire button_pad, // 连接到IOB
output reg button_pressed
);
// IOB输入寄存器(提高可靠性)
(* IOB = "TRUE" *)
reg button_sync1;
reg button_sync2;
// 两级同步器(跨时钟域或消除亚稳态)
always @(posedge clk) begin
if (rst) begin
button_sync1 <= 1'b0;
button_sync2 <= 1'b0;
end else begin
button_sync1 <= button_pad;
button_sync2 <= button_sync1;
end
end
// 消抖逻辑(省略)
// ...
endmodule2.5.2 LED驱动
module led_driver (
input wire clk,
input wire [7:0] led_data,
output reg [7:0] led_pad // 连接到IOB
);
// IOB输出寄存器(改善时序)
(* IOB = "TRUE" *)
always @(posedge clk) begin
led_pad <= led_data;
end
endmodule约束文件配置:
# LED驱动强度
set_property IOSTANDARD LVCMOS33 [get_ports {led_pad[*]}]
set_property DRIVE 8 [get_ports {led_pad[*]}]
set_property SLEW SLOW [get_ports {led_pad[*]}]2.5.3 高速DDR接口
module ddr_interface (
input wire clk,
input wire data_h, // 高半周期数据
input wire data_l, // 低半周期数据
output wire ddr_out_pad
);
// 使用ODDR原语
ODDR #(
.DDR_CLK_EDGE("OPPOSITE_EDGE")
) ODDR_inst (
.Q(ddr_out_pad),
.C(clk),
.CE(1'b1),
.D1(data_h),
.D2(data_l),
.R(1'b0),
.S(1'b0)
);
endmodule2.6 IOB相关的时序约束
2.6.1 输入延迟约束
# 输入信号的延迟约束
set_input_delay -clock [get_clocks sys_clk] -max 2.0 [get_ports {data_in[*]}]
set_input_delay -clock [get_clocks sys_clk] -min 0.5 [get_ports {data_in[*]}]2.6.2 输出延迟约束
# 输出信号的延迟约束
set_output_delay -clock [get_clocks sys_clk] -max 3.0 [get_ports {data_out[*]}]
set_output_delay -clock [get_clocks sys_clk] -min 1.0 [get_ports {data_out[*]}]2.6.3 IOB寄存器约束
# 强制将寄存器放入IOB(提高时序性能)
set_property IOB TRUE [get_ports {data_out[*]}]2.7 IOB使用的最佳实践
-
输入信号同步:
- 外部异步信号应使用两级触发器同步,防止亚稳态
-
输出寄存器:
- 关键输出信号应在IOB寄存器中寄存,减少时序路径
-
合理分配Bank:
- 提前规划引脚分配,确保同一Bank的I/O标准兼容
-
差分信号:
- 使用专用的差分对引脚,确保P/N信号匹配
-
保留未使用的引脚:
- 配置上/下拉电阻,防止悬空
-
EMI考虑:
- 对于低速信号使用SLOW转换速率
- 降低不必要的驱动强度
2.8 常见问题与解决
问题1:Bank电压冲突
- 现象:综合时提示”I/O Standards are incompatible in Bank XX”
- 解决:检查该Bank的所有引脚,确保VCCO设置和I/O标准一致
问题2:Setup/Hold时序违例
- 现象:时序报告显示输入或输出路径违例
- 解决:
- 添加IOB寄存器
- 调整
set_input_delay/set_output_delay约束 - 使用更快的I/O标准
问题3:信号完整性问题
- 现象:高速信号出现过冲、振铃
- 解决:
- 降低驱动强度
- 使用SLOW转换速率
- 添加串联端接电阻
- 考虑差分信号
3. 可编程互连资源(Programmable Interconnect Resources)
布线资源连通FPGA内部的所有单元,而连线的长度和工艺决定着信号在连线上的驱动能力和传输速度。FPGA 芯片内部有着丰富的布线资源,根据工艺、长度、宽度和分布位置 的不同而划分为4类不同的类别。第一类是全局布线资源,用于芯片内部全局时钟和全局复位/置位的布线;第二类是长线资源,用以完成芯片Bank间的高速信号和第二全局时钟信号的布线;第三类是短线资源,用于完成基本逻辑单元之间的逻辑互连和布线;第四类是分布式的布线资源,用于专有时钟、复位等控制信号线。
4. 硬核IP(Hard IP)
5. 全局网络(Global Network)
一个设计中某个信号的扇出(Fanouut)达到一定数量时,该信号就可以视为全局网络。一个设计中最容易出现大量Fanout信号大致有以下几类:
- 时钟信号:
- 时钟信号是FPGA设计中最重要的信号之一,它用于同步所有数字电路的运行。时钟信号的扇出通常非常大,因为需要驱动大量的寄存器和逻辑门。在单一时钟的同步电路中它覆盖着整个FPGA设计
- 复位信号:
- 复位信号用于将所有寄存器和逻辑门初始化为一个已知状态。大量使用复位电路会给整个设计在布局布线上造成极大的困难和麻烦,需要合理区分哪些电路需要复位哪些电路不用
- 使能信号:
- 使能信号用于控制寄存器和逻辑门的运行。使能信号的扇出通常也很大,因为需要驱动大量的寄存器和逻辑门。
- 清零信号:异步复位,同步使能等。